Mar 31
前面已经学习过第三章3.5节《字符型数据》,现在学习3.6节《变量赋初值》。
1、谭师傅说,“C语言允许在定义变量的同时使变量初始化“。又把“声明”当了“定义”。
2、谭师傅还说,“也可以使被定义的变量的一部分赋初值”。如果不看后面的例子,估计谁也不明白谭师傅讲的“变量的一部分”是什么部分。原来,谭师傅的意思是,“int a, b, c=5”这样的语句只对变量 c 赋初值。原来这就叫做“变量的一部分”啊。
3、谭师傅又教导我们说,“静态储存变量和外部变量的初始化是在编译阶段完成的”。谭师傅的“谭氏编译器”真是牛到不行了,程序还没运行就能初始化变量了。
接下来是第3.7节《各类数值型数据间的混合运算》。
4、谭师傅在讲什么是“数值型数据”时讲了整型、浮点型、字符型,漏了枚举型。本来嘛,按K&R,所有这些都叫做“算术类型”,不就很清楚了吗?按“谭氏分类法”,连谭师傅自己也不免考虑不周。
5、 谭师傅教导我们说,“float型数据在运算时一律先转换成双精度型,以提高运算精度”。不幸的是,前半句只对ANSI C之前的K&R C成立。在标准C中,两个float做算术运算时已经不会再转换成double。而后半句则完全是错的。K&R C里做了这样的转换只不过是因为当时Unix运行的硬件上有内置的双精度型,所以用双精度型反而比单精度型要快。与此类似的是char和short在表达 式中自动转成int。都是因为提高速度而不是提高精度。
接下来是第3.8节《算术运算符和算术表达式》。
6、谭师傅把运算符分了很多类,看起来是按运算符的“功能”分的,着实下了一番工夫。不过,C运算符的真正重要之处,即优先级和结合性,谭师傅没有仔细讲,只教人去看附录。有几个学生读课本时会去仔细研究附录?
7、谭师傅把做为负号的-和作为减法的-当成了同一个运算符来讲,实在是不应该。
8、谭师傅说,“如果参加+、-、*、/运算的两个数中有一个实数或双精度数,则结果是double型,因为所有实数都按double型进行运算”。看了 这句话,让我以为谭师傅在讲Fortran还是什么的,反正不是C。因为C语言里没有“实数”这个类型,也没有什么“所有实数都按double型进行运算 ”的规则。如果说C的“实数”是指所有可做算术运算,又非整数的数,那么它就应该包括“long double”,其精度不会比double低,因此在运算时如果有一个是long double,结果也是long double。
9、谭师傅在谈到“强制类型转换”时说,“在强制类型转换时,得到一个所需类型的中间变量”。这个“中间变量”不知道是什么神奇的东西。课后思考题:中间变量是变量吗?
好了,今天就学到这里,下次再学。
Mar 30
前面学到了第三章第3.4节。现在来学第3.5节,《字符型数据》。这一节谭师傅暴露出来的最大问题,就一句话,他不明白字符常量的类型是int。此节出现种种奇谈怪论,下面一一道来。
1、谭师傅教导我们说,“字符型变量用来存放字符常量“,并且举例说,“ char c1; c1=’a'; ”。事实上,’a'是一个int,应当用int c1 = ‘a’才是正确的做法。
2、谭师傅又一次给出了强悍的谭氏标准:“所有编译系统中都规定以一个字节来存放一个字符,或者说一个字符变量在内存中占一个字节“。事实上,ANSI C只规定了字符型的最大、最小值。
3、谭师傅又花了整整一小节来说明对字符也可以像对整数一样进行算术运算。如果谭师傅把字符型也归到整型一类,不早就万事大吉了吗?
4、谭师傅说,“应注意字符数据只占一个字节,它只能存放0~255范围的数据“。一句话两处错。字符数据的大小C标准只有最小值规定,在所有系统中都能保证的取值范围也只有0~127。
5、谭师傅给出一个用字符变量做算术运算的例子,把一个字符变量减去32后就从小写字母得到大写字母。可惜的是,标准C并不保证小写字母和大写字母之前相差32,甚至都不保证字母表是以连续的整数来表示。所以这又是一个不可移植的C程序的范例。
6、谭师傅说,char c = “a”这样的语句是”错误的“,因为“不能把一个字符串常量赋给一个字符变量“。我不知道师傅这里“错误的”是什么意思,因为这样的语句是可以编译通过的(尽管有警告),因此语法上是正确的。这个语句也没有把什么“字符串常量”赋给变量,而是把这个字符串的首个字符地址赋给变量 。
7、谭师傅语重心长地说,“有些人不能理解:’a'和”a”究竟有什么区别“。我看,这只怕是要归功于谭师傅自己。如果讲清楚了’a'是int,”a”是数组,那还有什么不好理解?
好了,第3.5节就学习到这里,下次继续。
Mar 27
之前已经学习了第三章3.1节和3.2节。现在接着学习第三章。
第3.3节
1、谭师傅花了很大一段讲什么是补码。我认为讲得还算清楚。不过,很可惜的是,整型数据在内存中如何存放,这不是标准C的一部分,而是取决于具体的硬件。为了让C程序可移植,ANSI C标准中从来没有规定过数据在内存中如何存放,将来也不可能。
2、谭师傅一会说有三种整型,一会又说有六种。这也就罢了。在学习3.2节时,我们已经提到过,整型应该包括字符、枚举,因为C语言里并不把这几种类型区别对待。像谭师傅这样讲法,有可能让人以为字符和枚举是什么特殊类型。
3、同上面第一点,有符号整型的第一位是否是符号位同样取决于具体硬件。
4、谭师傅说,一个int变量取值范围是-32768 ~ 32767。很可惜,这也是错的。一个int变量取值范围随编译环境不同而不同。ANSI C规定编译器必须提供一个<limits.h>,其中包含各种整数类型的大小。ANSI C还规定,对于int类型,最小的取值范围是 -32767 ~ 32767。谭师傅还不厌其烦地列出了TC的各种整型数据取值范围。这些在TC上是成立的。如果换了一个系统,就只有自求多福了。
5、谭师傅还花了一个小节来讲整型数据溢出时会发生什么事。这里的这句“将变量b改成long型…“已经多为人诟病,就不再提了。但其实最关键的问题在于,当数据溢出时会发生什么事,实际上在ANSI C标准中是undefined,也就是说发生任何事都有可能,取决于具体的编译、运行环境。
第3.4节
6、对于浮点型,同样,标准C并不要求数据在内存中以何种形式、用多少空间来存放。
7、谭师傅教导我们说,“ANSI C并未具体规定每种类型数据的长度、精度和数值范围”。实际上,ANSI C要求编译器提供一个<float.h>,其中必须包括关于浮点类型的信息,并对最低精度作了规定。比如,标准C要求float类型最少有6位有效数字,最少能表达10的37次方大小的数字,能表达的最小正整数是10的负5次方,等等。
8、标准C并不要求double的精度一定比float高,long double精度一定比double高,而只规定了这三种类型后一种精度不能比前一种低。
9、谭师傅说,“用程序计算1.0/3.0*3的结果并不等于1“。很遗憾的是,这又一次证明了谭师傅喜欢想当然,不上机实验。TC运行结果,1.0/3.0*3确实等于1。虽然谭师傅讲的关于精度的问题确实值得注意,但用错误的例子并不能说明问题。
小结一下:把可移植的C变成了不可移植的C,谭师傅功不可没。
好了,第3.3和3.4节学习完了,下次接着学。
Mar 26
之前已经学习了第二章,现在来看第三章,《数据类型、运算符与表达式》。
第3.1节:
1、谭师傅说,struct是C语言提供的数据结构。这里还得有请谭师傅“翻译”一下所谓的“数据结构”是个什么东西,不然此类“谭氏术语”看得多了之后,头都会大三圈的。
2、谭师傅还把C语言里的数据类型分成了几大类,可谓标新立异,用心良苦。现在让我们来欣赏一下“谭氏C语言类型“(如下图)。
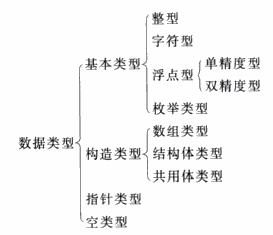
通常,我们都会把谭师傅所说的基本类型叫做算术类型,因为这些类型的数据可以进行加、减、乘、除的运算,而不是像谭师傅那样把指针当成一更”高级“的类型。另外,谭师傅所谓的“整型”,大概是包括int, short int 以及long int。在标准C里,这些类型和字符型、枚举型一并称为“Integral Type”(中文ANSI C标准译为“整型”,但容易和int类型搞混),因为所有这些类型都可以用整数来表示。谭师傅所谓“构造类型”中的结构体和共用体,我们一般称之为“复合类型”,因为它们可以将不同类型的数据组合到一起。最后,C语言里没有什么“空类型”。换句话说,C不允许没有类型的类型。当然,谭师傅很有可能指的是“void”。不过,void可不能单独使用。void*表示可以指向任何类型的指针,void函数表示函数不返回值,而函数形参用void则表示函数不带参数。不知道谭师傅所谓的“空类型”是哪一种?
第3.2节:
3、例3.1中,谭师傅先定义了PRICE,再#include<stdio.h>。这样也不能说不对,但养成了习惯就不太好。
4、谭师傅说,符号常量不能被赋值,不过没有讲为什么不能被赋值。作为努力寻求知识的学生,我很希望看到谭师傅讲清楚#define 实际上是做了替换,把PRICE换成了30,这样,不能写30=40这样的语句不就很清楚了吗?
5、谭师傅说,PRICE的“作用域”(姑且认为师傅讲的是scope)在例3.1中是主函数。我看了心里一阵嘀咕。符号常量有“作用域”吗?当preprocessor把PRICE换成了30后,它就是一个常数。常数有什么“作用域”?还是“主函数”?
6、谭师傅在讲到变量时教导我们说,“由编译系统给每一个变量分配对应的内存地址“。嗯,让我想想,如果有一函数f,它里面用到了一个局部变量a,但这个函数从来没被调用过,那么这个a有被分配内存地址吗?如果有被调用过呢?是“编译系统”给分配的吗?
7、我也很希望谭师傅能够在讲变量时加一句,尽可能不要使用下划线开头的变量名,以免和系统定义的标识符冲突。很遗憾,没有看到。
8、谭师傅还斩钉截铁地说,“ANSI C标准没有规定标识符的长度“。这一句话让我赶快把K&R又翻出来看了一下。还好,C还是那个可移植的C。C89规定了一般标识符最少要识别31个字符,并区分大小写(external的6个字符不分大小写)。谭师傅提到PC上的MS C不知道是什么年代的古董,只认8个字符。我劝谭师傅还是把那破玩艺砸了,把字节都掰成比特扔掉。“建议变量名的长度最好不要超过8个字符“这种“谭氏C标准”还是留给师傅自己用吧。
9、谭师傅还举了几个长变量名的例子,例如student-name和student-number。且慢,这两个不是是非法变量名么?
10、虽然谭师傅提倡用长变量名,要见名知义,不过呢,师傅“在一些简单的举例中,为了方便起见,仍用单字符的变量名“。还好我心细,看到了这句,不然还以为写这些例子的是个菜鸟。
11、谭师傅又一次把“声明”说成“定义”。咳,说什么好呢。
12、最后,有一处错误信息里的“Undefined“被拼成了”Undifeed“。还好大多数人也就只看前三个字母,无伤大雅,无伤大雅。
好了,第3.1节和3.2节就学习到这里。下次接着学。
Mar 25
之前已经学习过第二章的总论,现在继续学习。由于第二章整个内容极简单,也和C语言本身没什么太大关系,这里把第二章所有小节一并学习。以下是学习心得。
1、在2.1节中,谭师傅强调了“数值运算算法”和“非数值运算算法”的区别,并说数值运算算法“研究比较深入”,“算法比较成熟”,而非数值运算算法则“难以规范化“,“往往需要…重新设计解决特定问题的专门算法“。我不知道谭师傅有没有哪怕是尝试过学习Java/J2EE、C#/.NET,以及PHP、Perl、Python、Ruby等等语言及其相应framework。不知道谭师傅对它们所包含的“非数值运算算法”是怎么看的。就C或C++而言,不知道谭师傅对于STL、Boost、MFC、WDK等等是个什么看法。不过,考虑到谭师傅用的是TC,我们也不好勉为其难是不是?
2、在2.2节中,谭师傅给出了几个简单算法的例子。例2.1后面的解释中,谭师傅说“S1,S2代表步骤1,步骤2“,那么,前面出现的“步骤S3“是不是要理解成”步骤步骤3“?
3、在利用例2.1讲了循环之后,谭师傅教导我们说,“由于计算机是高速进行运算的自动机器,实现循环是轻而易举的,所有计算机高级语言中都有实现循环的语句,因此,上述算法不仅是正确的,而且是计算机能实现的较好的算法”。其实,算法要写成循环形式,恰恰是因为这样让程序员容易懂,而不是让机器容易懂。这才能解释为什么比较抽象的高级语言可以写出各种各样的循环语句而低级的汇编语言则只有有限几种。再进一步说,把循环语句改写成不循环的语句(loop unrolling)正是程序优化的一个重要手段。这就说明了循环语句绝不总是“计算机能实现的较好的算法”。
4、例2.3要求判定2000到2500年每一年是否闰年,并输出结果。这里谭师傅给出了如下算法:
S1: 2000=>y
S2: 若y不能被4整除,则输出y“不是闰年”。然后转到S6
S3: 若y能被4整除,不能被100整除,则输出y“是闰年”。然后转到S6
S4: 若y能被100整除,又能被400整除,输出y“是闰年”,然后转到S6
S5: 输出y“不是闰年“
S6: y+1=>y
S7: 当y<=2500时,转S2继续执行,否则算法停止。
这里有两个问题。一个是S2和S3中间的句号应该是逗号,否则“然后转到S6”就变成了无条件地转。按谭师傅在2.3节中算法应没有歧义的要求,这个算法是不及格的。第二个问题在于,S3和S4中的第一个条件判断是多余的。如果在程序中写上这样多余的判断,只会让程序更难懂。
5、从例2.1到例2.3,谭师傅一直都是用的“x=>y”来表示把x的值赋于y。到了例2.4,谭师傅突然又用了“x=y”的形式。乘法也直接就用星号(*)来表示。例2.5是更是“=>”和“=”混用。真是让人无所适从。虽然这是讲C语言的书,但谭师傅也要事先交代一下这里的“=”和“*”是什么意思,是不是?
6、在2.3节中,谭师傅说算法应该包含“有限的操作步骤”,然后又进一步说,“如果让计算机执行一个历时1000年才结束的算法,这虽然是有穷的,但超过了合理的限度,人们也不把它视为有效的算法“。我猜谭师傅从来没有研究过什么是复杂度,否则不会这样混淆算法的定义(或算法的有效性)和算法的效率和可行性。
7、谭师傅说,算法应“有零个或多个输入”。通常中文里说“多个”都是指“两个或以上”。那谭师傅的意思是仅有一个输入的不是算法?从后文来看,显然不是这样的。所以我只能理解为谭师傅想重造中文语法。而且,由于不可能有“负”个数的输入,这个所谓的“特性”就是废话一句。
8、第2.4节大部分内容实践当中用不着,就不多说了。只是其中又出现了几种不同的缩进风格(如例2.21)要留意。在该节最后,谭师傅又教导我们说,“应当强调说明的是,写出了C程序,仍然只是描述了算法,并未实现算法。只有运行程序才是实现算法”。如此精辟,不能不单独拿出来欣赏。我开始有点明白谭师傅在第一章里说C语言是一种“系统描述语言”是什么意思了。果然是博大精深。
9、在2.5节中谈到程序设计时,谭师傅很明显对于自下而上的方法不屑一顾,认为那是错的。他说,“有些人胸有全局…叫做自顶向下,逐步细化…另有些人写文章时不写提纲,如同写信一样提起笔就写,想到哪里就写到哪里,直到他认为把想写的内容都写出来了为止。这种方法叫做至下而上,逐步积累“,又说,“用第一种方法考虑周全,结构清晰,层次分明…这就是用工程的方法设计程序“。这么一段话,可以说是真正暴露了谭师傅对于稍大规模开发没有经验,也对工程设计没有概念,以为上面能设计出来的,下面就一定能实现。
好了,第二章就学习到这里了,下次接着学。
Mar 24
之前已经学习完第一章,现在开始学习第二章,《程序的灵魂--算法》。现在就从第二章的总论开始学习。以下是我的心得。
1、最让我惊讶的,是谭师傅居然把Niklaus Wirth的名写成了Nikiklaus。牵狗查了一下,有“Nikiklaus Wirth”字样的还不少,都是中文网站,有课件也有文章。不禁让我想起《蜘蛛侠》中的一句台词:“With great power, comes great responsibility”。谭师傅好歹也算是个名人,要注意一下影响。
2、不光是名字,谭师傅把那句名言也整反了。人家说的明明是“算法+数据结构=程序“,谭师傅一下就整成了”数据结构+算法=程序“。虽然说加法有交换律,不过呢,这可不是一个公式,而是一本书的名字。还是那句话,要注意一下影响。
3、谭师傅把数据结构比作食材,把算法比作烹饪的步骤,把算法提高到“灵魂”的高度,而认为“数据结构”只是“加工对象”。虽然没有明说,但给人的印象确实是“算法就是一切”,而数据结构则成了固定、死板、不需要太费心的东西。看到这里,我除了叹气以外也无话可说。算法与数据结构从来都是相辅相成,必需同时设计。一个好的数据结构能够极大的简化算法,并且让程序更容易读懂,更容易维护。这也正是为什么说“算法+数据结构=程序“的原因。这本来是任何一个合格的软件工程师都应该明白的东西。难怪网上有人劝谭师傅先自己试着做做软件开发再来写书。
4、本来算法和数据结构是独立于具体的编程语言、环境的(即同一个算法或数据结构可以用不同的语言实现)。也正是因为这样,算法、数据结构以至于算法复杂度等等概念才有研究的必要。在特殊情况下,某种语言甚至可以看成是专门为了某种算法和数据结构才被发明的。谭师傅这本书本来是讲C语言的,为什么不能专注于C语言呢?讲自己不擅长的东西也是对读者不负责。从整第二章来看,谭师傅眼中的“算法”,大概也就是先做A,再做B,如果C成立再回头做A之类的东西,还处于社会主义初级阶段。同学们可千万要记住了,“革命尚未成功,同志仍須努力“。
好了,概论就学习到这里。下次仔细分析谭师傅的算法。
Mar 23
前面已经学习过1.3节,现在来学习1.4节,《运行C语言的步骤与方法》,也是第一章最后一节。以下是学习心得。
1、谭师傅说,“所谓程序,就是一组计算机能识别和执行的指令。每一条指令使计算机执行特定的操作。”,后面紧接着又说“计算机…不能识别和执行高级语言写的指令”。
心得:由第一句对程序的定义和后面紧接着的这句话,我恍然大悟:原来C语言写的那不叫程序啊,不对,这本书明明叫做《C程序设计》的,我晕了。
2、谭师傅教导我们说,要“上机运行”一个C语言程序,必须先“在纸上写好一个程序后“,再…
心得:天啊,这难道是学英语时单词写得不够多的报应?
3、谭师傅说,“目前使用的大多数C编译系统都是集成环境(IDE)的”。
心得:谭师傅这一句话漏了自己的底:对UNIX是七窍通了六窍。当然,后面还有其它的心得可以佐证。
4、谭师傅又教导我们说,“不应当只会使用一种编译系统,而对其他的一无所知。“
心得:结合上一条心得,我心里那个汗哪。
5、谭师傅用的文件名都是诸如c1.c、c2.c、f.exe等等。
心得:够简洁、够有力,够雷人。
6、谭师傅说,“Turbo C++…也能编译以.c为后缀的C源程序(按照Turbo C++的语法规定进行编译)”。
心得:莫非Borland公司自己创造了一套C语言语法?还是谭师傅在为 (a=3*5)=3*4 这样的“谭氏表达式”作伏笔?
7、谭师傅在第一章结束的题目中,要求学生“根据自己的认识,写出C语言的主要特点“。又问,“C语言的主要用途是什么?它和其它高级语言有什么异同?“
心得:我若是谭师傅的学生,一定会不知所措。还没学会呢,哪来的什么”认识“?如果原来没学过什么其它高级语言,又哪里来的什么异同?原来学C语言也是背书?
好了,第一章学习完毕,以后接看学。
Mar 20
前面已经学习过第1.2节。现在接着学习第1.3节,《简单的C语言程序介绍》。
这一节以三个简单的C程序为例,讲解了C语言的基本结构、语法,以及初步的函数的概念。看得出有刻意求新的地方,比如很有味道的“Hello World”就变成了枯燥无味的“This is a C program.”。
这一节的主要学习心得如下:
1、变量是在“声明”的时候就“定义”了,不管有没有同时给它赋值。如例1.2和1.3的注释部分,以及谭师傅在解释例1.2时对“int a,b,sum;”讲解说它“是声明部分,定义变量a和b,指定a和b为整型“。
2. 一行可以写好几个语句,只要写得下。
3、函数返回值的类型也可以叫做“函数的类型”。
4、一个函数所调用的函数是在本身函数体的声明部分声明的。
当然,以上心得都是作为反面案例来学习的。
好了,1.3节就学习到这里了。以后接着学习。
注:原本有更多的心得,是针对第二版写的。现在发现第三版已经改了不少,所以就以第三版为准了。
Mar 20
看了新到中这篇文章之后很是诧异。短短三段话,错误一大堆。以下是我的评论:
1、C和C#是两个完全不同的语言。除了语法看起来有点像之外,没有任何可比性。谭的书可是讲的C语言,勉强把C++拿来说说也罢,C#是怎么冒出来的?
2、1999年的C标准(实际上是ISO C而不是ANSI C,通常称之为C99)实际上是C语言“最新”的标准,而不是什么“古老的东西”。而且在网上最多只能找到这个标准的草稿。毕竟人家ISO要拿来卖的。
3、事实上,最容易获得的是C89。这是因为C89已经包含在C语言的“圣经”,K&R第二版里面了。这本书就算是正版价格也不贵,相信张云楼老师还是买得起的。
4、目前C标准只有三个版本,C89、C90以及C99。没有哪一个标准允许switch带非整数参数(注意是整数不是整型)。不管是什么标准,找个C编译器(如谭师傅推荐的古董TC)试试不就好了?最好的莫过gcc,因为用它编译时可以指定用哪一版本的标准。
5、从g3like列出的C#中switch可以接受的类型来看,除了string,其它也都可以表达为整数。如果可以相信这个列表是完整的,那么就算是在C#里switch也不能接受“任何类型”吧?“也许是正确的”这样的诊断从何而来?
6、 实事上,C语言的switch可以接受的类型除了整型、字符型和枚举型以外,还包括短整型、长整型、长长整型,以及所有这些的有符号和无符号的类型。也就 是说,g3like列出的C#接受类型中,只有string是C语言里没有的类型以外,其它的相对应的C类型都可以被C语言的switch接受。
7、C++里面的switch也同样不能接受整数类型以外的类型。
Mar 19
之前已经学习过1.1节,现在再来学习1.2节,“C语言的特点”。
谭师傅说C语言“数据结构丰富,具有现代化语言的各种数据结构“。我看到这里就蒙了。C语言里只有数组还可算得上是个“数据结构”,丰富在哪里啊?再往下看,原来谭师傅说的是C的“数据类型”丰富,可以实现复杂的数据结构。这都哪跟哪啊?我是不是也可以说汇编语言的“数据结构丰富”,因为用汇编也可以实现各种复杂的数据结构?
谭师傅说C的“语法限制不太严格”。与C相对的,“一般的高级语言语法检查比较严,能检查出几乎所有的语法错误。而C语言…放宽了语法检查“。我就不懂了,语法检查不是编译器干的事么?如果一个编译器不能检查出所有的语法错误,那一定是假冒伪劣产品。写C语言程序还能不按它的语法规则写?我又一次看到了“谭氏编译器”的身影。
谭师傅还匠心独具地解释了一番“高级语言中的低级语言”和“中级语言”,并认为C语言一般被称为“高级语言”,原因是它必需“通过编译、连接才能得到 可执行的目标程序”。“目标程序”这个词不伦不类,暂且不提。难道谭师傅写的汇编程序(如果他写的话)是不需要经过编译和连接就可以得到可执行程序的?这样看来,不光有谭氏C编译器,还有谭氏assembler。
在第二版中,谭师傅还列出几种语言作为高级语言的例子,其中居然连一个functional language都没有。试想,如果BASIC和FORTRAN算是高级语言,那C++/Java/C#不就成了超高级语言,而Lisp、Prolog、ML就成了超超高级语言了(说起来怎么这么绕口:))。还好第三版里这些被去掉了。
谭师傅还提到“UNIX和C不可分”。话是没错,不过谭师傅为什么还在用TC?
直看到这一节结束,谭师傅对诸如Linux、Java、C#等等只字未提(像PHP之类就不强求了),只讲BASIC、PASCAL、FORTRAN、COBOL如何如何,让人不禁想起七、八十年代的美好时光。
谭师傅还认为,C++只是编写大型软件用的,没必要一开始就学,而且学了C再学C++就很容易,因为“面向对象的基础是面向过程”。真的是这样吗?C和C++各有所长,但绝不是什么大型还是小型的问题。OOP与Procedure Programming之间的关系也绝非谁是谁的基础这么简单。
好,1.2节学习完毕。下次接着学习。