第1.1节 C程序的形式
如果你已经习惯了诸如Pascal语言那样的块结构的程序形式,那么,C程序外围的布局可能会让你感到惊异。如果你过去的经历主要是在FORTRAN阵 营,那么你会觉得C程序在外围和你熟知的东西比较接近,但内层看起来仍然截然不同。C语言恬不知耻地从这两种语言里借了不少东西,当然也从其它很多地方借 了东西。众采百家造就了有点像杂交猎犬的语言:不甚优雅,但有着一种招人喜欢的野性魅力。生物学家称之为“杂交优势”。这也可能让你联想到“嵌合体”,即 诸如绵羊和山羊的杂交体之类的人工混合种。如果它既出羊毛又产奶,那固然是好,不过很有可能它只会臭哄哄地咩咩叫!
从最粗糙的层面来说,C语言的一个显著特征,就是程序的多文件结构。C语言支持独立编译,也就是说,一个完整程序的各个部分可以存放在一个或多个源文件里,而这些源文件可以分开单独编译。然后,编译产生的文件再由系统提供的链接编辑程序(link editor)或装入程序(loader)来把它们链接到一起。类似于Algol的语言就不同,它里面的块结构要求整个程序是放在一起的。尽管通常有办法绕过这种要求,但还是不利于独立编译。
C语言的这种做法有其历史原因,也是相当有趣的。它的本意是追求更快的速度。基本的构想是这样的:把一个程序编译成可重新定位的目标代码非常慢,又耗费资 源;编译是很繁重的工作。如果用一个装入程序来把几个目标代码模块绑定到一起,那么应该只需要在把这些模块合并成完整程序时计算一下模块中每一项的绝对地 址就可以了。这应当是相对简单的。由此推广下去,很明显,还可以让装入程序来扫描目标代码库并取其所需。这样做的好处在于,如果你只修改了整个程序的很小一部分,那么就不必浪费资源去重新编译整个程序,因为只有被你的修改影响到的部分需要被重新编译。
尽管如此,当装入程序承担了越来越多的任务之后,它也就越来越慢。事实上,有时它有可能成为整个过程中最慢、最费事的一环。在某些系统中,重新编译所有程 序完全有可能比使用装入程序更快。Ada语言有时会被人当作这种效应的例子。而对于C语言来说,装入程序要做的事情不多,所以采取这种做法是明智的。图1 中显示的是这种做法的工作原理。
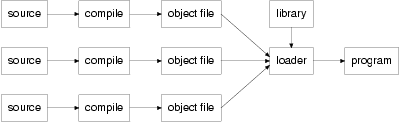
图1 独立编译 (source:源程序;compile:编译;object file:目标文件;library:函数库;loader:装入程序;program:程序)
这种技术对于C语言来说是很重要的。因为在C语言里,除了最小的程序之外,所有程序都分散在不同的源文件里。另外,对于新手来说,初看之下不太明显的一个地方,就是由于C语言大量使用函数库,即使是极简单的程序也需要通过装入程序才能够运行。
1.2 函数
一个C语言程序的组成部分,包括一些函数,还有一些大致上可以称为全局变量的东西。当这些东西在程序里被定义的时候,它们就被赋予了名字。而如何在程序的某个地方通过这些名字来使用这些东西,则是有一定规则的。这些规则在C语言标准中被称之为连接(linkage)。目前我们暂时只用知道外部连接和没有连接是 什么意思。说一样东西有外部连接,意思就是它在整个程序中都可以使用(库函数就是很好的例子)。没有连接的东西也是被广泛使用的,只不过它们的使用有更为 严格的限制。在函数内部使用的变量对于该函数来说通常是“本地”的,也就是说它们是没有连接的。虽然本书尽量避免使用诸如此类的复杂术语,但是有的时候没 法讲得更简单了。到后面,你将会熟悉连接的概念。目前,我们只有在用函数时才会遇到外部连接。
C语言中的函数等同于FORTRAN语言中的函数或子程序,也等同于Pascal和ALGOL语言中的函数和过程。BASIC语言的大多数简单变体,以及COBOL语言,都没有可以和C语言中的函数相提并论的概念。
很明显,函数的作用就是让你可以把一个构思或操作封装起来,给它起一个名字,然后在程序其它各个地方只需要使用这个名字就可以调用这个操作。在使用函数的 时候是看不到里面的细节的,也不应该能看到。在设计精良、结构合理的程序中,只要函数要做的事情不变,就应当可以改变函数做事的方法而不影响程序的其它部 分。
在主机环境中,有一个函数有着特殊的名称,即叫做main的函数(主 函数)。这个函数是程序开始运行后进入的第一个函数。在独立环境中,程序开始运行的方式则取由编译系统定义(译注1.1)。所谓“由编译系统定义”,意思是说,尽管C语言标准不对具体行为作出规定,但是这些行为必须是一致的,而且是有案可查的。当主函数结束时,整个程序就结束了。以下是一个程序例,里面包 含两个函数。
#include <stdio.h>
/*
* 告诉编译器我们要使用一个叫做 show_message 的函数。
* 这个函数没有参数,而且不返回任何值。
* 这就是函数的“声明”.
*
*/
void show_message(void);
/*
* 另一个函数,不过这次包含了函数体。
* 这就是一个“定义”。
*/
main(){
int count;
count = 0;
while(count < 10){
show_message();
count = count + 1;
}
exit(0);
}
/*
* 那个简单函数的函数体。
* 这次就是“定义”了。
*/
void show_message(void){
printf("hellon");
}
例 1.1